
*注:本博文为JVM中常见的GC的各种特性的大概总结,并非注重其实现细节。
原创整理笔记,作者VioletTec;QQ:595585575
若想要了解GC的各种细节,推荐一个链接:
JVM深入学习 - 随笔分类 - cexo - 博客园 (cnblogs.com)
👆该分类下的文章全都是JVM的纯理论知识,有兴趣可以自行仔细阅读。
1. 什么是GC?
垃圾收集器(Garbage Collector):在计算机科学中,垃圾回收(英语:Garbage Collection,缩写为GC)是指一种自动的存储器管理机制。当某个程序占用的一部分内存空间不再被这个程序访问时,这个程序会借助垃圾回收算法向操作系统归还这部分内存空间。垃圾回收器可以减轻程序员的负担,也减少程序中的错误。垃圾回收最早起源于LISP语言。[1][2]目前许多语言如Smalltalk、Java、C#Go和D语言都支持垃圾回收器。
A (garbage) collector is (an implementation of) a garbage collection algorithm.
1.1 GC中一些名词解释
- 并行 与 并发
- 并行:JVM的GC中,并行一般指的是GC线程的多线程运行
- 并发:JVM的GC中,并发一般指的是GC线程与用户线程(mutator)同时运行。
2. JVM中常见的GC收集器有哪些?它们有什么特色?
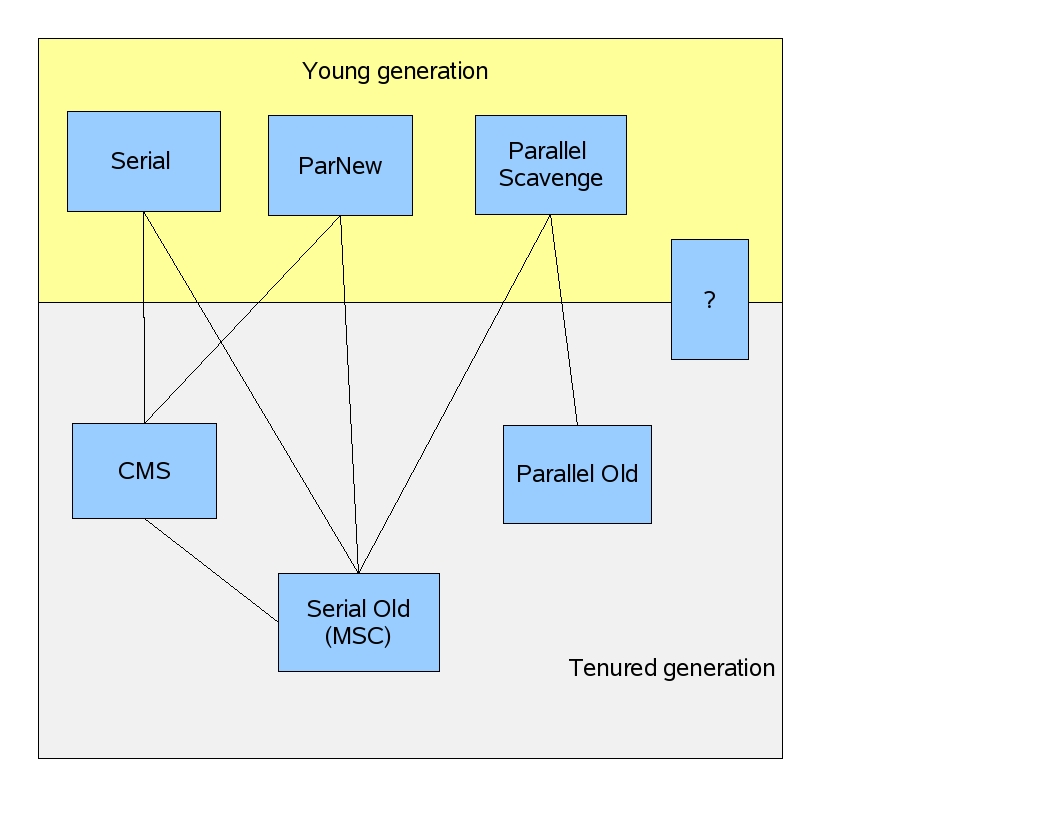
- Serial收集器
- Parallel收集器
- ParNew收集器
- CMS收集器
- G1收集器
- ZGC收集器
- Shenandoah收集器

2.1 Serial收集器
(串行收集器【单线程垃圾处理器】)
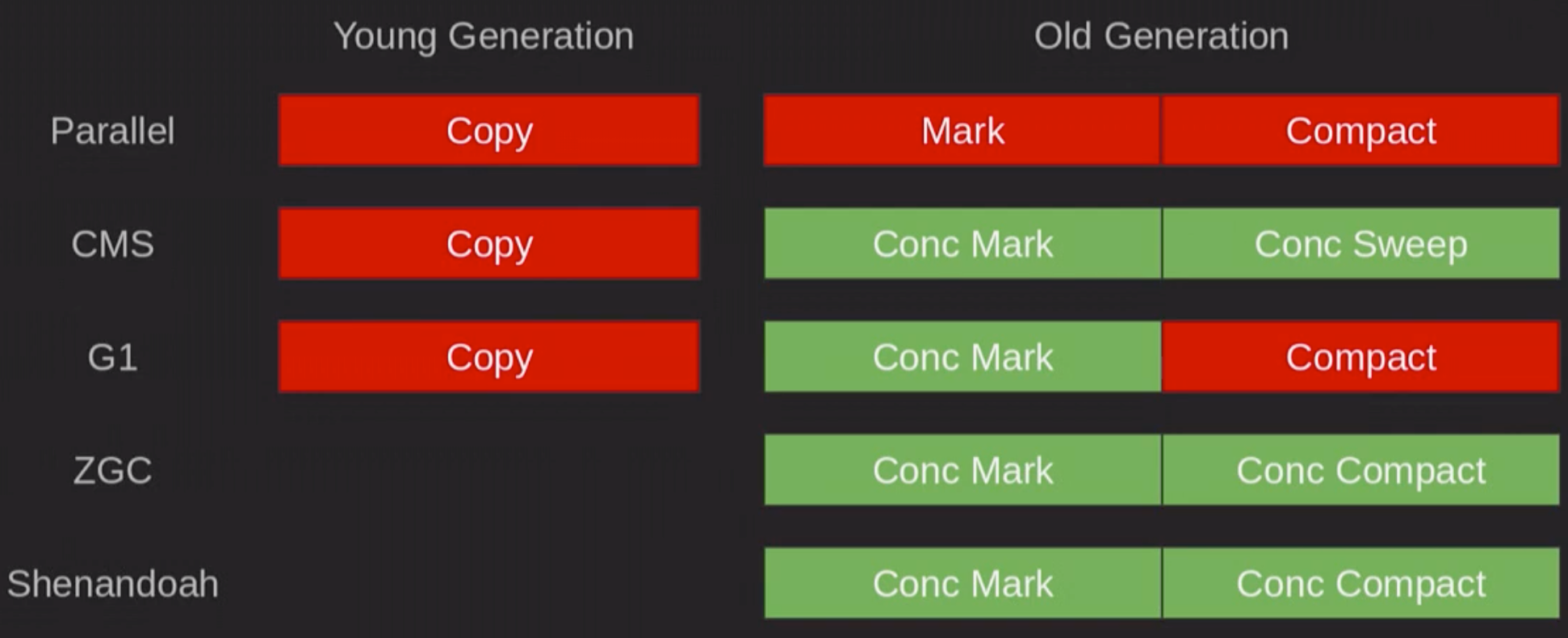
- 分代算法:
- 年轻代:Serial - 复制算法(copy)
- 老年代:SerialOld - 标记 - 清除 - 压缩算法(mark-compress)
- 特点:
- 优点:
- 串行收集器是最古老
- 最稳定以及效率高的收集器
- 缺点:
- 可能会产生较长的停顿
- 只使用一个线程去回收
- 分代线程:
- 新生代、老年代使用串行回收
- 启用参数: -XX:+UseSerialGC
2.2 Paralell收集器
(并行收集器【多线程垃圾处理器】)
- 分代算法:
- 年轻代:Parallel Scavenge - 复制算法(copy)
- 老年代:Parallel Old - (mark-compress)
- 特点:
- 类似 ParNew, 更加关注吞吐量。停顿时间短,回收效率高。
- 启用参数:
- -XX:+UseParallelGC
(Parallel收集器 + 老年代串行) - -XX:+UseParallelOldGC (Parallel收集器 + 老年代并行)【默认】
| 使用的命令 / 对应代使用的算法及运行方式 | 新生代(yong gen) | 新生代运行方式 | 老年代(old gen) | 老年代运行方式 |
|---|---|---|---|---|
| -XX:+UseParallelGC | ParallelScavenge | 并行 | SerialOld(又称:PSMarkSweep) | 串行 |
| -XX:+UseParallelOldGC | ParallelScavenge | 并行 | ParallelOld(又称:PSCompact) | 并行 |
| 并行收集器相关参数 | 描述 |
|---|---|
| -XX:+UseParallelGC | Full GC采用parallel MSC (此项待验证) |
| -XX:+UseParNewGC | 设置年轻代为并行收集 |
| -XX:ParallelGCThreads | 并行收集器的线程数 |
| -XX:+UseParallelOldGC | 年老代垃圾收集方式为并行收集(Parallel Compacting) |
| -XX:MaxGCPauseMillis | 每次年轻代垃圾回收的最长时间(最大暂停时间) |
| -XX:+UseAdaptiveSizePolicy | 自动选择年轻代区大小和相应的Survivor区比例 |
| -XX:GCTimeRatio | 设置垃圾回收时间占程序运行时间的百分比 |
| -XX:+ScavengeBeforeFullGC | Full GC前调用YGC |
2.2.1 SerialOld(PSMarkSweep)收集器
- PSMarkSweep = “ParallelScavenge的MarkSweep”,其实只是在serial GC的核心外面套了层皮而已,骨子里是一样的LISP2算法的mark-compact收集器(别被名字骗了,它并不是一个mark-sweep收集器,而是一个mark-sweep-compact收集器)。
2.2.2 ParallelOld(PSCompact)收集器
- PSCompact(=“ParallelScavenge-MarkCompact”),LISP2算法的并行版的full GC收集器,收集整个GC堆。
2.2.3 Parallel Scavenge回收器
- >+ Parallel Scavenge(简称PS)并没有遵循generational GC framework进行开发,而是自己定义了一套接口和实现细节。
>
- ParallelScavenge其实已经名不符实了——它不只并行化了“scavenge”(minor GC),也并行化了“mark-compact”(full GC)。
- PSScavenge跟ParNew是对等的东西;ParallelScavenge这个名字既指代整套新GC,也可指代其真正卖点的PSScavenge。
- Parallel Scavenge和ParNew抽象来说是同一思路的GC,而后者可以跟CMS搭配使用(因为Parallel Scavenge没有遵循分代式GC框架——generational GC framework,所以无法与CMS中的新生代算法)。这样就够了。
- 新生代收集器,复制算法,并行收集,面向吞吐量要求(吞吐量优先收集器)。
- 吞吐量 = 用户代码运行时间 /(用户代码运行时间+垃圾回收时间)
- -XX:MaxGCPauseMillis:控制最大垃圾收集停顿时间,大于零的毫秒数。
- -XX:GCTimeRatio:吞吐量大小,0到100的整数,垃圾收集时间占总时间的比例,计算1/(1+n)gc时间占用比例。
- -XX:UseAdaptiveSizePolicy:打开之后,就不需要设置新生代大小(-Xmn),Edian,survivor比例及(-XX:SurvivorRatio)晋升老年代年龄(-XX:PretenureSizeThreshold),虚拟机根据系统运行状况,调整停顿时间,吞吐量, GC自适应调节策略,区别parnew。
- 其实最初的ParallelScavenge的目标只是并行收集young gen,而full GC的实际实现还是跟serial GC一样。只不过因为它没有用HotSpot VM的generational GC framework,自己实现了一个CollectedHeap的子类ParallelScavengeHeap,里面都弄了独立的一套接口,而跟HotSpot当时其它几个GC不兼容。其实真的有用的代码大部分就在PSScavenge里,也就是负责minor GC的收集器;而负责full GC的收集器叫做PSMarkSweep。
2.3 ParNew收集器
ParNew收集器其实就是Seral收集器的并行(多线程)版本。其算法与Serial收集器一致,只不过是多线程并发收集。是HotSpot虚拟机中第一款真正意义上的并发收集器。
- 分代算法:
- 年轻代:复制算法(copy)
- 老年代:标记 - 清除 - 压缩算法(mark-compress)
- 特点:
- 优点:
- 并行收集,在多核CPU中的效率要优于Serial收集器。
- 能与CMS收集器配合使用。
- 缺点:
- ParNew收集器在单CPU的环境中绝对不会有比Serial收集器更好的效果,甚至由于存在线程交互的开销,该收集器在通过超线程技术实现的两个CPU的环境中都不能百分之百地保证能超越Serial收集器。
- 分代线程:
- 新生代、老年代使用并行回收
- 启用参数: -XX:+UseParNewGC -XX: +UseConcMarkSweepGC(ParNew收集器也是使用该选项后的默认新生代收集器)
| 并行收集器相关参数 | 描述 |
|---|---|
| -XX:+UseParallelGC | Full GC采用parallel MSC (此项待验证) |
| -XX:+UseParNewGC | 设置年轻代为并行收集 |
| -XX:ParallelGCThreads | 并行收集器的线程数 |
| -XX:+UseParallelOldGC | 年老代垃圾收集方式为并行收集(Parallel Compacting) |
| -XX:MaxGCPauseMillis | 每次年轻代垃圾回收的最长时间(最大暂停时间) |
| -XX:+UseAdaptiveSizePolicy | 自动选择年轻代区大小和相应的Survivor区比例 |
| -XX:GCTimeRatio | 设置垃圾回收时间占程序运行时间的百分比 |
| -XX:+ScavengeBeforeFullGC | Full GC前调用YGC |
2.4 CMS收集器
CMS - Concurrent Mark Sweep 收集器,以获取最短回收停顿时间【也就是指Stop The World的停顿时间】为目标,多数应用于互联网站或者B/S系统的服务器端上。其中“Concurrent”并发是指垃圾收集的线程和用户执行的线程是可以同时执行的。
CMS GC下 会在特殊情况(jvm认为内存不够了concurrent mode failure,promotion fail) 转而停下所有线程去做full gc,也就是MSC(单线程)就是Serial Old(也算一次full gc)作为替补,速度较慢。也就是说,老年代算法有两个,其中CMS算法是主力算法,Serial Old算法为后备算法 。
- 分代算法:
- 年轻代:复制算法(copy)
- 老年代:标记 - 清除(mark-sweep)或 【在使用Serial Old收集器的时候】标记 - 清除 - 压缩(mark-compress)
- 特点:
- 优点:并发收集、低停顿【注意:这里的停顿指的是停止用户线程】,Oracle公司的一些官方文档中也称之为并发低停顿收集器(Concurrent Low Pause Collector)。
- 缺点:
1、CMS收集器对CPU资源非常敏感。
2、CMS收集器无法处理浮动垃圾(Floating Garbage,就是指在之前判断该对象不是垃圾,由于用户线程同时也是在运行过程中的,所以会导致判断不准确的, 可能在判断完成之后在清除之前这个对像已经变成了垃圾对象,所以有可能本该此垃圾被回收但是没有被回收,只能等待下一次GC再将该对象回收,所以这种对像就是浮动垃圾),可能出现“Concurrent Mode Failure”失败而导致另一次Full GC的产生。如果在应用中老年代增长不是太快,可能适当调高参数-XX:CMSInitiatingOccupancyFraction的值来提高触发百分比,以便降低内存回收次数从而获取更好的性能。要是CMS运行期间预留的内存无法满足程序需要时,虚拟机将启动后备预案:临时启用Serial Old收集器来重新进行老年代的垃圾收集,这样停顿时间就很长了。所以说参数-XX:CMSInitiatingOccupancyFraction设置得太高很容易导致大量“Concurrent Mode Failure”失败,性能反而降低。
3、收集结束时会有大量空间碎片产生,空间碎片过多时,将会给大对象分配带来很大麻烦,往往出现老年代还有很大空间剩余,但是无法找到足够大的连续空间来分配当前对象,不得不提前进行一次Full GC。CMS收集器提供了一个-XX:+UseCMSCompactAtFullCollection开关参数(默认就是开启的),用于在CMS收集器顶不住要进行Full GC时开启内存碎片的合并整理过程,内存整理的过程是无法并发的,空间碎片问题没有了,但停顿时间不得不变长。 - 分代线程:
- 新生代:CMS是一个针对老年代的收集器,新生代可以配合ParNew或者Serial收集器
- 老年代:使用并发回收
- 启用参数: -XX:+UseConcMarkSweepGC(使用ParNew作为新生代算法,Serial Old收集器作为老年代的后备算法)。
| CMS相关参数 | 类型 | 默认值 | 描述 |
|---|---|---|---|
| -XX:+UseConcMarkSweepGC | boolean | false | 老年代采用CMS收集器收集 |
| -XX:+CMSScavengeBeforeRemark | boolean | false | The CMSScavengeBeforeRemark forces scavenge invocation from the CMS-remark phase (from within the VM thread as the CMS-remark operation is executed in the foreground collector). |
| -XX:+UseCMSCompactAtFullCollection | boolean | false | 对老年代进行压缩,可以消除碎片,但是可能会带来性能消耗 |
| -XX:CMSFullGCsBeforeCompaction=n | uintx | 0 | CMS进行n次full gc后进行一次压缩。如果n=0,每次full gc后都会进行碎片压缩。如果n=0,每次full gc后都会进行碎片压缩 |
| –XX:+CMSIncrementalMode | boolean | false | 并发收集递增进行,周期性把cpu资源让给正在运行的应用 |
| –XX:+CMSIncrementalPacing | boolean | false | 根据应用程序的行为自动调整每次执行的垃圾回收任务的数量 |
| –XX:ParallelGCThreads=n | uintx | 并发回收线程数量:(ncpus <= 8) ? ncpus : 3 + ((ncpus * 5) / 8) | |
| -XX:CMSIncrementalDutyCycleMin=n | uintx | 0 | 每次增量回收垃圾的占总垃圾回收任务的最小比例 |
| -XX:CMSIncrementalDutyCycle=n | uintx | 10 | 每次增量回收垃圾的占总垃圾回收任务的比例 |
| -XX:CMSInitiatingOccupancyFractio=n | uintx | jdk5 默认是68% jdk6默认92% | 当老年代内存使用达到n%,开始回收。CMSInitiatingOccupancyFraction = (100 - MinHeapFreeRatio) + (CMSTriggerRatio * MinHeapFreeRatio / 100) |
| -XX:CMSMaxAbortablePrecleanTime=n | intx | 5000 | 在CMS的preclean阶段开始前,等待minor gc的最大时间。see here |
| -XX:+UseBiasedLocking | boolean | true | Enables a technique for improving the performance of uncontended synchronization. An object is "biased" toward the thread which first acquires its monitor via a monitorenter bytecode or synchronized method invocation; subsequent monitor-related operations performed by that thread are relatively much faster on multiprocessor machines. Some applications with significant amounts of uncontended synchronization may attain significant speedups with this flag enabled; some applications with certain patterns of locking may see slowdowns, though attempts have been made to minimize the negative impact. |
| -XX:+TieredCompilation | boolean | false | Tiered compilation, introduced in Java SE 7, brings client startup speeds to the server VM. Normally, a server VM uses the interpreter to collect profiling information about methods that is fed into the compiler. In the tiered scheme, in addition to the interpreter, the client compiler is used to generate compiled versions of methods that collect profiling information about themselves. Since the compiled code is substantially faster than the interpreter, the program executes with greater performance during the profiling phase. In many cases, a startup that is even faster than with the client VM can be achieved because the final code produced by the server compiler may be already available during the early stages of application initialization. The tiered scheme can also achieve better peak performance than a regular server VM because the faster profiling phase allows a longer period of profiling, which may yield better optimization. |
2.5 G1收集器
G1收集器 - Garbage First收集器
使用了Region的概念,对每一个Region进行了分代。
- 分代算法:
- 新生代:与其他GC类似,使用标记-复制-清除算法。
- 老年代:当进行Full gc时是serial模式,采用 标记-清除-压缩 算法。
- - 优点:
- 软实时、低延迟、可设定目标
- JDK9+默认GC(JEP248)(JEP 248: Make G1 the Default Garbage Collector (java.net))
- 适用于较大的内存( > 4 ~ 6 G)
- 用于代替CMS
- 缺点:
- 老年代和年轻代的跨代引用(老年代可能会持有年轻代的引用)
- 不同Region之间的相互调用
- 空间换时间
- 用额外的空间维护引用信息
- 5%~10% memory overhead
- 分代线程:
- 新生代:并行
- 老年代:并发
- 当
mixed gc回收速度赶不上内存分配的速度,G1会使用单线程(使用Serial Old的代码)进行Full GC。 - 启用参数: -XX:+UseG1GC
| G1的相关参数 | 介绍 |
|---|---|
| -XX:+UseG1GC | 启用G1收集器 |
| -XX:G1HeapRegionSize | 设置G1堆内存大小(2048 by default【默认2048个region】) |
| -XX:MaxGCPauseMillis=n | 设置回收的最大时间 |
| -XX:G1NewSizePercent=n | 设置年轻代最小使用的空间比率,默认为Java堆 内存的5% |
| -XX:G1MaxNewSizePercent=n | 设置年轻代最大使用的空间比率,默认为Java堆内存的6% |
| -XX:ParallelGCThreads=n | 设置STW工作线程数的值,与使用的CPU数量有关,最大值为8。如果CPU数量超过八个,则最多可以设置总CPU数量的“5/8”。 |
| -XX:ConcGCThreads=n | 设置并行标记线程数 |
| -XX:InitiatingHeapOccupancyPercent=n | 设置占用区域的百分比,超过此百分比将触发GC操作,默认为45% |
| -XX:NewRatio=n | 设置年轻代与老年代的比率(Young + Tenured),默认为2 |
| -XX:SurvivorRatio=n | 设置Eden与Survivor的比率(Eden 。Survivor),默认为8 |
| -XX:MaxTenuringThreshold=n | 新生代保存到老年代的岁数 |
| -XX;G1ReservePercent=n | 设置预留空间的空闲百分比,以降低目标空间的溢出风险,默认为10% |
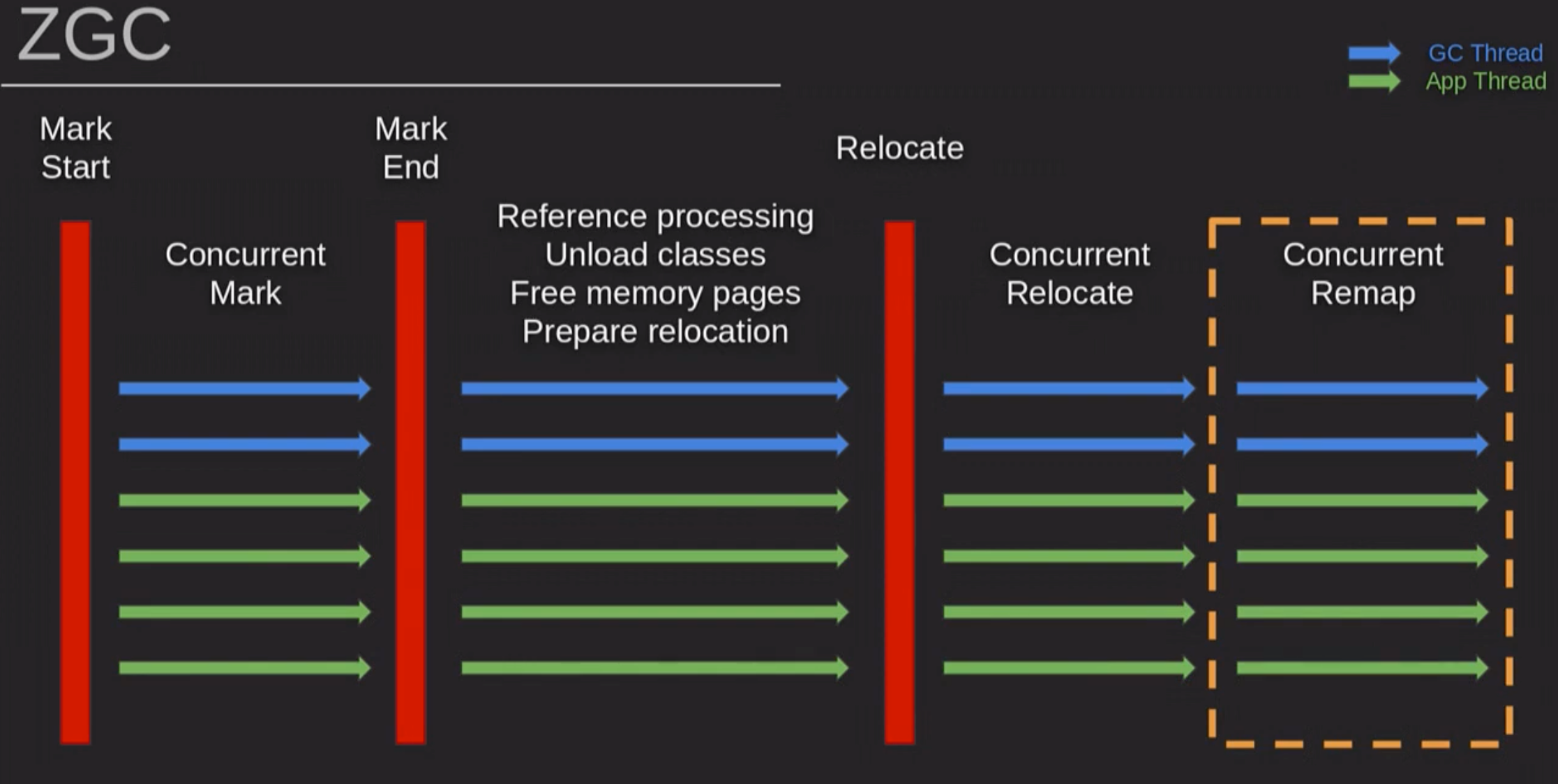
2.6 ZGC收集器
ZGC - A Scalable Low Latency Garbage Collector
- 分代算法:
- ZGC无分代
- - 优点:
- STW停顿时间极短,一般不会超过1ms。(虽然官网的数据是小于10ms)
- 缺点:
- 为了保证STW时间足够短,ZGC会牺牲吞吐量(官方的数据是不会超过15%)。一般应用未必用到ZGC,尤其是Web应用。
- ZGC仅实现了单代内存管理,也就是说没有考虑热点数据与冷数据,这个在商业的C4已经支持。据说Auzl实现的分代内存管理器比没有分代的内存管理器效率高10倍(并没有找到相关的资料文献),也就是说ZGC还有巨大的进步空间;
- 分代线程:
- ZGC无分代,全程几乎都在并发,只有很小的一段时间STW,所以会牺牲吞吐量。
- 启用参数: -XX:UseZGC
- 其他参数:
- -XX:ZCollectionInterval 固定时间间隔进行gc,默认值为0。
- -XX:ZAllocationSpikeTolerance
内存分配速率预估的一个修正因子,默认值为2。一般不需要更改 - -XX:ZProactive 是否启用主动回收策略,默认值为true。一般建议开启
- -XX:ZMarkStackSpaceLimit
(jdk12才有的参数):Maximum number of bytes allocated for mark stacks - -XX:ZUncommit
(jdk13才有的参数):Uncommit unused memory - -XX:ZUncommitDelay
(jdk13才有的参数):Uncommit memory if it has been unused for the specified amount of time (in seconds)
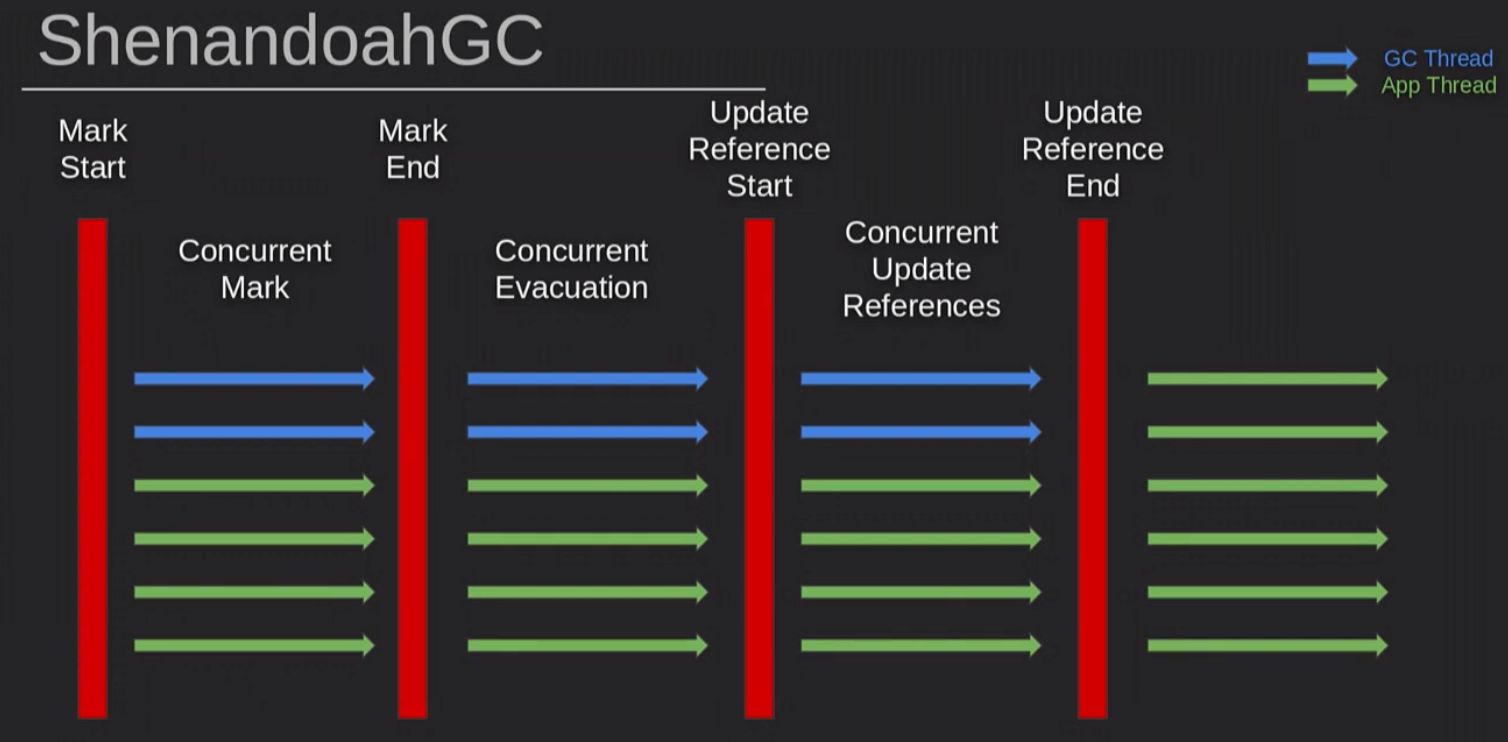
2.7 Shenandoah收集器
Shenandoah is the low pause time garbage collector
- 分代算法:
- Shenandoah GC 无分代
- - 优点:
- 设计目标是将垃圾回收的停顿时间控制在 10ms 以内,大部分阶段都是并发执行,仅有初始标记和最终标记会造成 STW,并且这两个阶段停顿的时间都十分短暂,因此 Shenandoah 在进行垃圾回收时造成的系统延时非常低,确实是一款以低延时为目标的垃圾回收器。
- 没有像 G1 那样使用卡表来维护记忆集,而是采用了“连接矩阵”来记录对象之间跨分区的引用关系,这在很大程度下降低了垃圾回收器对系统内存的占用以及负载。
- 缺点:
- 在 Shenandoah 中,通过 Brooks Pointer 转发指针来实现对象访问的问题,这种解决方式最明显的缺点就是每次访问对象都需要经过一次指针转发,对系统资源消耗过大。
- 高运行负担使得吞吐量下降;使用大量的读写屏障,尤其是读屏障(题外话:在内存屏障中,写屏障的开销大于读屏障),增大了系统的性能开销。
- 分代线程:
- Shenandoah 无分代,大部分阶段都是并发执行,仅有初始标记和最终标记会造成 STW。
- 启用参数: -XX:+UseShenandoahGC
3. JVM垃圾收集器相关参数总结
以下参数基于JDK 8整理
| 收集器 | 参数 | 描述 |
|---|---|---|
| Serial | -XX:+UseSerialGC | 虚拟机在Client模式下的默认值,开启后,使用 Serial + Serial Old 的组合 |
| ParNew | -XX:+UseParNewGC | 开启后,使用ParNew + Serial Old的组合 |
| -XX:ParallelGCThreads=n | 设置垃圾收集器在并行阶段使用的垃圾收集线程数,当逻辑处理器数量小于8时,n的值与逻辑处理器数量相同;如果逻辑处理器数量大于8个,则n的值大约为逻辑处理器数量的5/8,大多数情况下是这样,除了较大的SPARC系统,其中n的值约为逻辑处理器的5/16。 | |
| Parallel Scavenge | -XX:+UseParallelGC | 虚拟机在Server模式下的默认值,开启后,使用 Parallel Scavenge + Serial Old的组合 |
| -XX:MaxGCPauseMillis=n | 收集器尽可能保证单次内存回收停顿的时间不超过这个值,但是并不保证不超过该值 | |
| -XX:GCTimeRatio=n | 设置吞吐量的大小,取值范围0-100,假设 GCTimeRatio 的值为 n,那么系统将花费不超过 1/(1+n) 的时间用于垃圾收集 | |
| -XX:+UseAdaptiveSizePolicy | 开启后,无需人工指定新生代的大小(-Xmn)、 Eden和Survisor的比例(-XX:SurvivorRatio)以及晋升老年代对象的年龄(-XX:PretenureSizeThreshold)等参数,收集器会根据当前系统的运行情况自动调整 | |
| Serial Old | 无 | Serial Old是Serial的老年代版本,主要用于 Client 模式下的老生代收集,同时也是 CMS 在发生 Concurrent Mode Failure时的后备方案 |
| Parallel Old | -XX:+UseParallelOldGC | 开启后,使用Parallel Scavenge + Parallel Old的组合。Parallel Old是Parallel Scavenge的老年代版本,在注重吞吐量和 CPU 资源敏感的场合,可以优先考虑这个组合 |
| CMS | -XX:+UseConcMarkSweepGC | 开启后,使用ParNew + CMS的组合;Serial Old收集器将作为CMS收集器出现 Concurrent Mode Failure 失败后的后备收集器使用 |
| -XX:CMSInitiatingOccupancyFraction=68 | CMS 收集器在老年代空间被使用多少后触发垃圾收集,默认68% | |
| -XX:+UseCMSCompactAtFullCollection | 在完成垃圾收集后是否要进行一次内存碎片整理,默认开启 | |
| -XX:CMSFullGCsBeforeCompaction=0 | 在进行若干次Full GC后就进行一次内存碎片整理,默认0 | |
| -XX:+UseCMSInitiatingOccupancyOnly | 允许使用占用值作为启动CMS收集器的唯一标准,一般和CMSFullGCsBeforeCompaction配合使用。如果开启,那么当CMSFullGCsBeforeCompaction达到阈值就开始GC,如果关闭,那么JVM仅在第一次使用CMSFullGCsBeforeCompaction的值,后续则自动调整,默认关闭。 | |
| -XX:+CMSParallelRemarkEnabled | 重新标记阶段并行执行,使用此参数可降低标记停顿,默认打开(仅适用于ParNewGC) | |
| -XX:+CMSScavengeBeforeRemark | 开启或关闭在CMS重新标记阶段之前的清除(YGC)尝试。新生代里一部分对象会作为GC Roots,让CMS在重新标记之前,做一次YGC,而YGC能够回收掉新生代里大多数对象,这样就可以减少GC Roots的开销。因此,打开此开关,可在一定程度上降低CMS重新标记阶段的扫描时间,当然,开启此开关后,YGC也会消耗一些时间。PS. 开启此开关并不保证在标记阶段前一定会进行清除操作,生产环境建议开启,默认关闭。 | |
| CMS-Precleaning | -XX:+CMSPrecleaningEnabled | 是否启用并发预清理,默认开启 |
| CMS-AbortablePreclean | -XX:CMSScheduleRemark EdenSizeThreshold=2M | 如果伊甸园的内存使用超过该值,才可能进入“并发可中止的预清理”这个阶段 |
| CMS-AbortablePreclean | -XX:CMSMaxAbortablePrecleanLoops=0 | “并发可终止的预清理阶段”的循环次数,默认0,表示不做限制 |
| CMS-AbortablePreclean | -XX:+CMSMaxAbortablePrecleanTime=5000 | “并发可终止的预清理”阶段持续的最大时间 |
| -XX:+CMSClassUnloadingEnabled | ||
| -XX:+ExplicitGCInvokesConcurrent | ||
| G1 | -XX:+UseG1GC | 使用G1收集器 |
| -XX:G1HeapRegionSize=n | 设置每个region的大小,该值为2的幂,范围为1MB到32MB,如不指定G1会根据堆的大小自动决定 | |
| -XX:MaxGCPauseMillis=200 | 设置最大停顿时间,默认值为200毫秒。 | |
| -XX:G1NewSizePercent=5 | 设置年轻代占整个堆的最小百分比,默认值是5,这是个实验参数。需用-XX:+UnlockExperimentalVMOptions解锁试验参数后,才能使用该参数。 | |
| -XX:G1MaxNewSizePercent=60 | 设置年轻代占整个堆的最大百分比,默认值是60,这是个实验参数。需用-XX:+UnlockExperimentalVMOptions解锁试验参数后,才能使用该参数。 | |
| -XX:ParallelGCThreads=n | 设置垃圾收集器在并行阶段使用的垃圾收集线程数,当逻辑处理器数量小于8时,n的值与逻辑处理器数量相同;如果逻辑处理器数量大于8个,则n的值大约为逻辑处理器数量的5/8,大多数情况下是这样,除了较大的SPARC系统,其中n的值约为逻辑处理器的5/16。 | |
| -XX:ConcGCThreads=n | 设置垃圾收集器并发阶段使用的线程数量,设置n大约为ParallelGCThreads的1/4。 | |
| -XX:InitiatingHeapOccupancyPercent=45 | 老年代大小达到该阈值,就触发Mixed GC,默认值为45。 | |
| -XX:G1MixedGCLiveThresholdPercent=85 | Region中的对象,活跃度低于该阈值,才可能被包含在Mixed GC收集周期中,默认值为85,这是个实验参数。需用-XX:+UnlockExperimentalVMOptions解锁试验参数后,才能使用该参数。 | |
| -XX:G1HeapWastePercent=5 | 设置浪费的堆内存百分比,当可回收百分比小于浪费百分比时,JVM就不会启动Mixed GC,从而避免昂贵的GC开销。此参数相当于用来设置允许垃圾对象占用内存的最大百分比。 | |
| -XX:G1MixedGCCountTarget=8 | 设置在标记周期完成之后,最多执行多少次Mixed GC,默认值为8。 | |
| -XX:G1OldCSetRegionThresholdPercent=10 | 设置在一次Mixed GC中被收集的老年代的比例上限,默认值是Java堆的10%,这是个实验参数。需用-XX:+UnlockExperimentalVMOptions解锁试验参数后,才能使用该参数。 | |
| -XX:G1ReservePercent=10 | 设置预留空闲内存百分比,虚拟机会保证Java堆有这么多空间可用,从而防止对象晋升时无空间可用而失败,默认值为Java堆的10%。 | |
| -XX:-G1PrintHeapRegions | 输出Region被分配和回收的信息,默认false | |
| -XX:-G1PrintRegionLivenessInfo | 在清理阶段的并发标记环节,输出堆中的所有Regions的活跃度信息,默认false | |
| Shenandoah | -XX:+UseShenandoahGC | 使用UseShenandoahGC,这是个实验参数,需用-XX:+UnlockExperimentalVMOptions解锁试验参数后,才能使用该参数;另外该参数只能在Open JDK中使用,Oracle JDK无法使用 |
| ZGC | -XX:+UseZGC | 使用ZGC,这是个实验参数,需用-XX:+UnlockExperimentalVMOptions解锁试验参数后,才能使用该参数; |
| Epsilon | -XX:+UseEpsilonGC | 使用EpsilonGC,这是个实验参数,需用-XX:+UnlockExperimentalVMOptions解锁试验参数后,才能使用该参数; |
参考资料:
- 新一代垃圾回收器:G1详解 - VioletTec's Blog (mcplugin.cn)
- ParNew 和 PSYoungGen 和 DefNew 是一个东西么? - 高级语言虚拟机 - ITeye群组
- Parallel Scavenge收集器为何无法与CMS同时使用?- 知乎
- 并发垃圾收集器(CMS)为什么没有采用标记-整理算法来实现? - 讨论 - 高级语言虚拟机 - ITeye群组
- ParNew收集器详解 - - ITeye博客
- 《深入理解Java虚拟机:JVM高级特性与最佳实践》
- CMS垃圾收集器深入详解 - cexo - 博客园 (cnblogs.com)
- 系统最常用的CMS GC mode——ParNew & CMS(Serial Old作为替补)(heap> 5g)
- JVM 之CMS参数大全 – – ITeye博客
- JVM并行收集器ParNew、Parallel相关参数
- JVM垃圾收集器相关参数
- JDK12中新版垃圾回收器-Shenandoah GC
- JVM系列之垃圾回收器(下篇)——Shenandoah垃圾回收器