
90Pan<https://www.90pan.com>是国内为数不多的非大厂还在运营的一家云盘
爬虫程序已经写好,放在Github - https://github.com/KeKe12030/Download90Pan
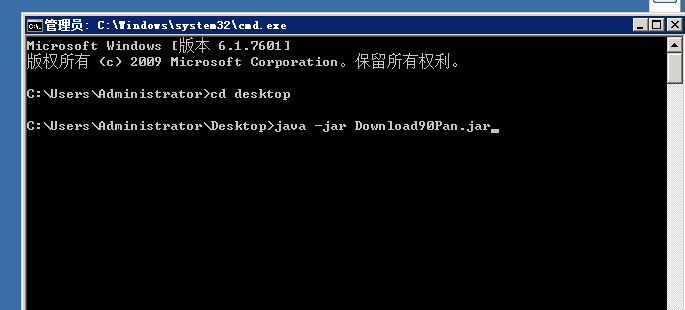
一下Download90Pan简称(D90)
前因
之前想要批量下载文件,使用Java+Jsoup实现爬虫,但是发现他家的下载链接是动态生成的,所以Jsoup无法满足我的需求,于是我想起来了前段时间我在开发疫情机器人爬虫的时候,也遇到了这个问题,当时成功的解决了,于是想起来了一个爬虫框架—— htmlunit
使用Htmlunit之后,发现我还是获取不到90Pan的下载链接,没有办法,只能另辟他径。
在一番搜索以后(什么?你问我为什么不百度?因为我有病(Bing)[狗头])
我发现了可以通过自动化控制Chrome来达到加载JS的爬虫效果——selenium 和 webdriver
所以在多次bing了一下,什么是selenium和webdriver,以及如何使用之后,终于获取到了90Pan的下载链接。程序已经写好,放在Github - https://github.com/KeKe12030/Download90Pan
** 你需要的依赖:selenium和chromedriver,具体如何下载,请你bing吧。
简单的介绍
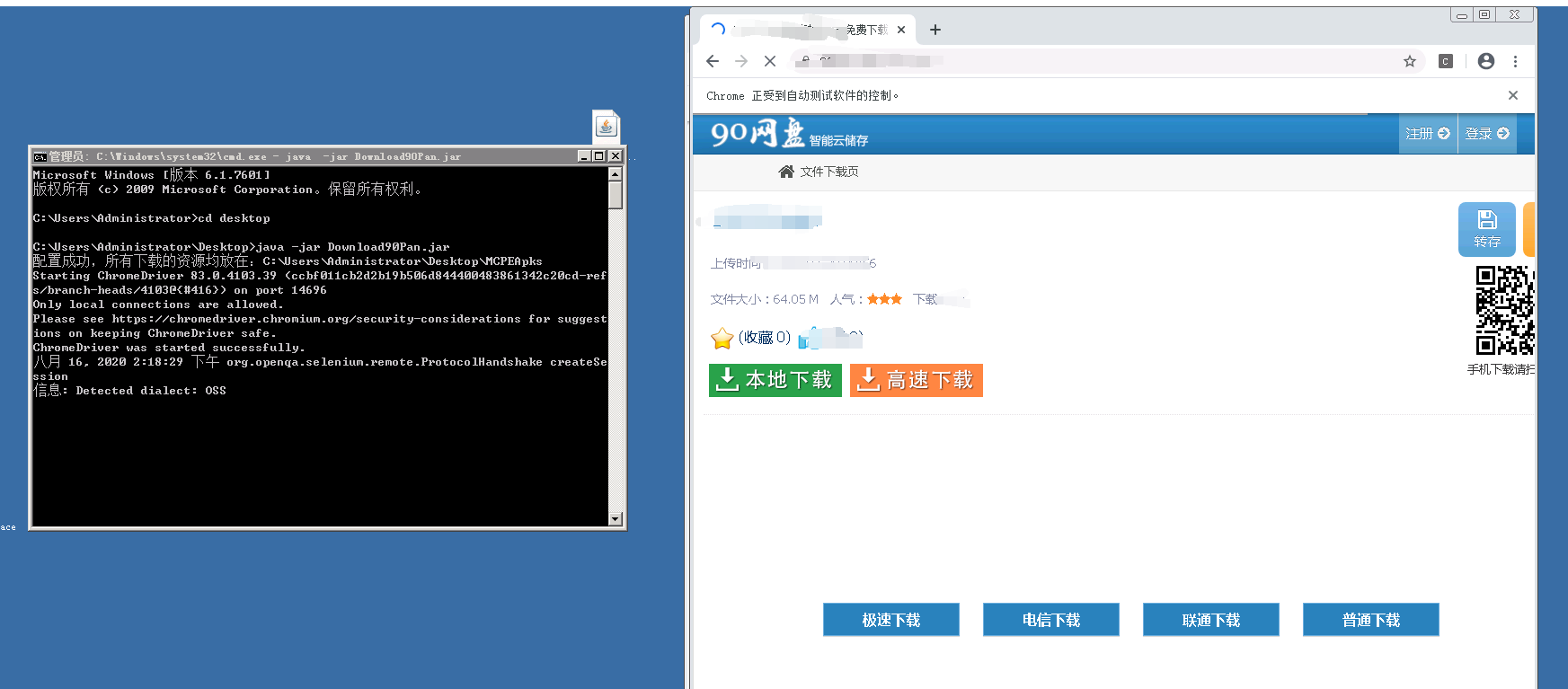
由于90Pan的安全策略吧,最大只能开5个线程,再多开一个就会报503,所以爬虫里我也只开设了5条线程来下载。
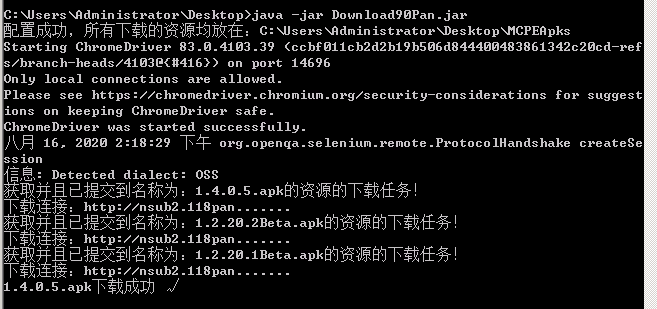
D90中的爬取资源详情链接和下载资源是两个不同的线程
爬取资源链接中又分为:
- 爬取资源具体详情链接(使用Jsoup,速度快)[FindSources.java]
- 爬去资源下载直链(使用selenium,速度较慢)[DownloadSource.java]
如果需要具体的需求,还可以在源码中进行修改。
DownloadSource使用的是一个BlockQuere阻塞队列,并且线程死循环判断是否size()>0,队列中如果有资源则取出后下载。
已知BUG
- 下载可能会中断,因为90Pan的下载链接是自动生成的,并且具有时效性,所以建议跑在拥有Chrome的Windows服务器上,并且网速和硬盘读写速度要快
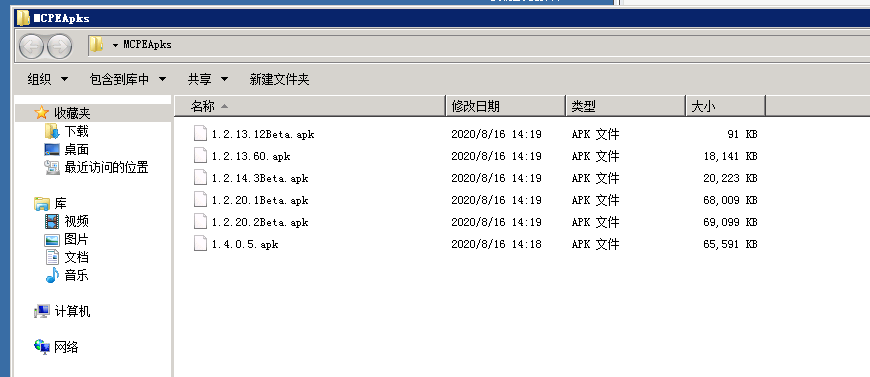
图片展示
结尾
文章还算半成品,没有写完,项目也是,最近电脑坏了,借来了一台电脑用来写文章+处理一些事情。所以D90进一步完善还需要等待一部分时间,等换电脑之后在继续完善文章和D90。
如果你有兴趣的话可以直接fork我的项目进行开发吧,记得开发的比较好之后提交。
等换好电脑之后我会在文章中配一些图片,以及更详细的文字教学,尽情期待吧。
更新了一些照片。
电脑换了台新的,环境全部重新装了,还好Github救了我的命,原来的电脑显卡应该是炸了,现在换了一台台式机,速度比原来2008年买的东芝不知道快到哪里去了,终于可以流畅的写BUG了。
不说了,借来了一台笔记本,插上我老的硬盘,我去迁移一些数据了。

哦豁,新鲜的kk,好巧啊
拿到新电脑了,最近要开学了,除了抄作业[划掉]还要忙一些项目更新,随缘更新咕咕咕。?️